

Buenas, tras la descarga e instalación de la herramienta RTMT para CUCM solo nos queda aprender alguna cosa sobre su funcionamiento y sobre cómo usarlo para monitorizar nuestros CUCM, sean cual sean el volumen de estos.
Como se puede decir que soy un “experto” en telefonía, pero esta herramienta es bastante nueva para mí, no os voy a dar todas las claves que necesitarías para monitorizar todo correctamente, sino que os daré cuatro pinceladas de cómo empezar a moveros.
Por cierto, aunque he dicho en uno de los post anteriores que lo mejor es usar el RTMT, os recomiendo poner algún otro sistema como por ejemplo SCOM, Nagios y Cacti (así lo tenemos nosotros) para que no se os escape ni una 😉
Arrancamos!
La ventana más importante ahora mismo es la inicial. En “System > Tools > Alert Central” tenemos todas las alarmas importantes. Tendremos alarmas como “Hardware Failure”, “Server Down”, “Critical Service Down”, “Cisco DRF Failire”, “Autentication Dailed”, “Low Swap Partition Available Disk Space”, y otras alertas, cuyo significado no hace falta comentar.
En caso de que todo vaya bien veremos todas las alarmas en color negro, en caso de ver fallos destacaran con un color rojo. En caso de caída podremos ver la hora a la que se ha producido.

Si nos posicionamos sobre una alerta y hacemos clic en “Alert Detail” podremos ver lo que ha sucedido con cierto grado de detalle.
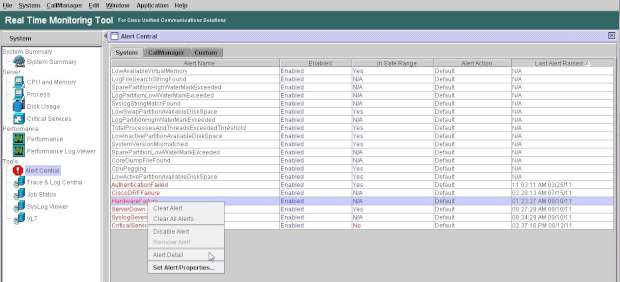
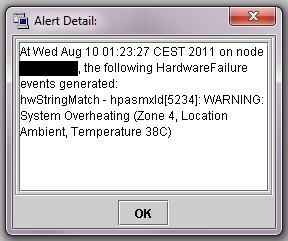
En este caso, un servidor ha detectado una temperatura ambiente de 38 grados por lo que ha sido apagado e manera cautelar.
Así mismo, si nos fijamos en el lateral inferior derecho de la pantalla, en caso de haber alertas, veremos un símbolo como el siguiente, que indica que hay alarmas.

Si nos posicionamos sobre esta, podremos ver que ha pasado sin tener que seleccionarla en el cuadro principal.
Otra cosa que podemos hacer es ver el estado del sistema en una visión resumen similar a la del administrador de tareas de Windows.
Para ver esta información debemos acceder a “System > System Summary > System Summary”.
En esta vista se muestra:
- Uso de la memoria virtual.
- Uso de la CPU.
- Uso de partición común.
Veremos una gráfica por cada servidor del cluster.

Accediendo a “System > Server > CPU and memory” podremos ver el estado de estos componentes en tiempo real.

Si accedemos a “System > Server > Process” tendremos una vista similar a un “TOP” en GNU/Linux.

En “System > Server > Disk Usage” tenemos el uso del disco duro de los CUCM. En concreto se muestra el uso de la partición común, la partición Sw2ap y de la partición de Spare.

En “System > Server > Critical Services” podemos ver si un servicio en concreto está levantado o no y podemos discriminar esta vista por servidor de cluster.
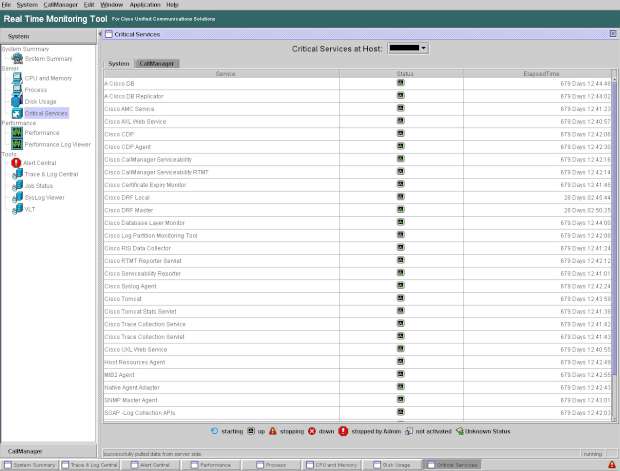
Otro tema a tener en cuenta es que en “System > Tools” tenemos los logs y dumps del sistema por lo que podemos obtener mucha información desde estos menús.

Es posible que dedique algún otro artículo a esta herramienta, y muy posiblemente será debido al uso de los logs.
Espero que os haya sido de utilidad.
Un saludo